
Der Infotext erklärt den Begriff „Topologischer Supraleiter“.
 Der Wissenscomic erklärt die Verschränkung auf anschauliche Weise. Alice und Bob entdecken die Funktionsweise der „Quanten-Zauberwürfel“, Kater Erwin kommentiert das Experiment und erklärt, was sich hinter dem Zauber verbirgt.
Der Wissenscomic erklärt die Verschränkung auf anschauliche Weise. Alice und Bob entdecken die Funktionsweise der „Quanten-Zauberwürfel“, Kater Erwin kommentiert das Experiment und erklärt, was sich hinter dem Zauber verbirgt.
Lehrkräfte können den Comic als PDF-Datei nutzen (siehe Button unten) oder in gedruckter Form im Klassensatz bestellen (> Link zum Warenkorb).
Weitere Unterrichtsmaterialien:
> HTML-Animation zu den Quanten-Zauberwürfeln, passend zur Geschichte im Comic
> Wissenscomic zum Thema Quantenkryptographie
Mit der HTML-Animation kann eine Serie von Würfen durchgeführt und ausgewertet werden.
Die Animation passt zur Geschichte im Wissenscomic 02: Die Quanten-Zauberwürfel.
Die Datei steht auch zum Download zur Verfügung (siehe Button unten).
Links: Chrom hat mit insgesamt sechs Spin-ungepaarten Elektronen in den äußeren 4s- und 3d- Orbitalen eine besondere Elektronenkonfiguration. Der Spin ist in der Abbildung als Pfeil dargestellt. Durch die ungepaarten Spins entsteht ein permanentes magnetisches Moment, das Chromatome magnetisch macht.
Rechts: Ein Chromatom (orange) auf einer Niob-Oberfläche (grau) führt durch die Wechselwirkung der Spins dazu, dass lokal die supraleitenden Cooper-Paare (blau) aufgebrochen werden. An dieser Stelle bilden sich diskrete Zustände aus, hier durch eine Wellenfunktion dargestellt. Wenn mit der Spitze des Rastertunnelmikroskops ein zweites Chromatom nahe an ein anderes gebracht wird, kommt es zunächst zur Wechselwirkung (rechts, Mitte) und dann zur Hybridisierung (rechts, unten) dieser Zustände.
© links: Küster F.; rechts: Küster, F. et al. Long range and highly tunable interaction between local spins coupled to a superconducting condensate. Nat Commun 12, 6722 (2021) // CC BY 4.0
Zwischen Spitze und Probe wird eine Spannung angelegt. Der messbare Tunnelstrom ermöglicht eine extrem präzise Positionierung der Spitze. Durch die Rückkopplung lässt sich im Konstanten-Strom-Modus eine topografische Karte der Probe mit atomarer Auflösung erstellen.
© F. Küster, MPI für Mikrostrukturphysik // CC BY-NC-SA 4.0
 Was sind topologische Supraleiter und weshalb sind sie so interessant für die Entwicklung von Quantencomputern? Das neue TECHMAX-Heft zeigt, wie Forschende versuchen, mit einem Rastertunnelmikroskop Atom für Atom einen topologischen Supraleiter aufzubauen. Ausgehend von den physikalischen Grundlagen der Rastertunnelmikroskopie erklärt das Heft, unter welchen Bedingungen topologische Supraleitung entsteht und wie es Forschenden gelingt, die bisher nur theoretisch vorhergesagten Strukturen tatsächlich zu erschaffen.
Was sind topologische Supraleiter und weshalb sind sie so interessant für die Entwicklung von Quantencomputern? Das neue TECHMAX-Heft zeigt, wie Forschende versuchen, mit einem Rastertunnelmikroskop Atom für Atom einen topologischen Supraleiter aufzubauen. Ausgehend von den physikalischen Grundlagen der Rastertunnelmikroskopie erklärt das Heft, unter welchen Bedingungen topologische Supraleitung entsteht und wie es Forschenden gelingt, die bisher nur theoretisch vorhergesagten Strukturen tatsächlich zu erschaffen.
Die Print-Ausgabe des Heftes ist ab Mitte Juni verfügbar. Vorbestellungen über den Warenkorb sind möglich.

© F. Küster, MPI für Mikrostrukturphysik
Forschende auf der ganzen Welt sind auf der Suche nach neuen Supraleitern. Diese besonderen Materialien können bei tiefsten Temperaturen Strom verlustfrei leiten und magnetisch zum Schweben gebracht werden. Während viele Forschende Supraleiter suchen, die diese Eigenschaften auch bei Raumtemperatur zeigen, gehen andere auf die Jagd nach topologischen Supraleitern. Denn die würden sich für wesentlich robustere Quantencomputer eignen.
Wie mit einem Greifarm liest Felix Küster mit der feinen Spitze seines Rastertunnelmikroskops ein Atom auf und zieht es über die Oberfläche des Supraleiters. An einer anderen Stelle legt er es gezielt ab. Nach und nach reiht er so Atome aneinander, erzeugt erst eine Kette, dann ein Gittermuster, das aussieht wie eine Tafel Schokolade. Felix Küster arbeitet als Wissenschaftler am Max-Planck-Institut für Mikrostrukturphysik in Halle. Dort ist das Rastertunnelmikroskop das Werkzeug seiner Wahl, um neuartige Supraleiter zu erforschen: „Mit dem Rastertunnelmikroskop kann ich mit Atomen Lego spielen und dadurch neuartige Materialien schaffen. So kann ich Quantenzustände manipulieren und auch genau untersuchen. Die Welt der Quanten wird also sichtbar und begreifbar.“
Das Herzstück eines Rastertunnelmikroskops (Abb. A) ist eine extrem feine Spitze aus einem leitenden Material, beispielsweise aus Wolfram. Extrem fein bedeutet hier, dass idealerweise ein einzelnes Atom an der Spitze sitzt. Die Spitze wird mit höchster Präzision nur circa 500 bis 1.000 Pikometer (10 -12 Meter) über der Oberfläche der zu untersuchenden Probe positioniert. Diese Lücke ist so klein, dass nur wenige Atome zwischen Spitze und Probe passen würden. Ein menschliches Haar ist etwa 100.000-mal dicker. Daher ist es sehr wichtig, dass das Rastertunnelmikroskop vor Schwingungen geschützt wird. Andernfalls könnten bereits die Schritte eines Menschen, der auf dem Gang vorbei geht, zu Messfehlern führen. Dazu wird das Mikroskop selbst besonders konstruiert und abgeschirmt aufgebaut, aber auch das Labor und das Gebäude selbst müssen besondere Voraussetzungen erfüllen.
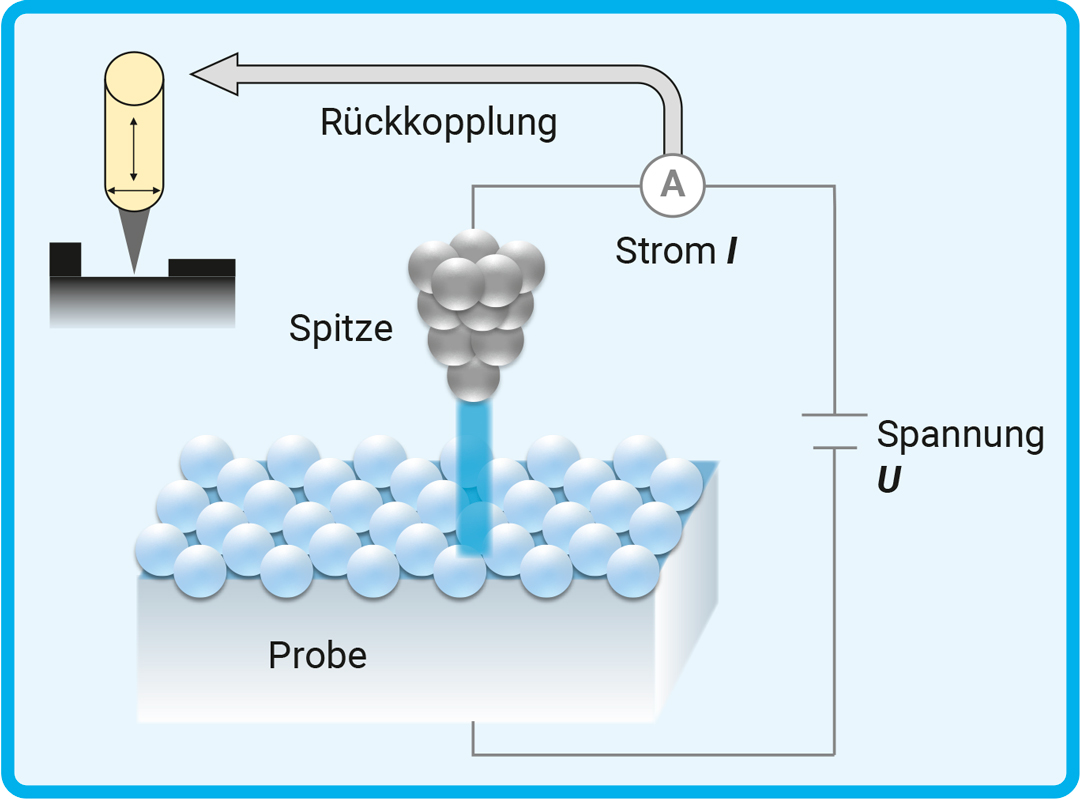
Abb. A: Rastertunnelmikroskop. Zwischen Spitze und Probe wird eine Spannung angelegt. Der messbare Tunnelstrom ermöglicht eine extrem präzise Positionierung der Spitze. Durch die Rückkopplung lässt sich im Konstanten-Strom-Modus eine topografische Karte der Probe mit atomarer Auflösung erstellen.
© F. Küster, MPI für Mikrostrukturphysik // CC BY-NC-SA 4.0
Zwischen der Spitze des Rastertunnelmikroskops und der Probe wird eine Spannung von typischerweise unter einem Volt angelegt. Die Stärke des Stroms, der dann gemessen werden kann, verrät, wie weit die Spitze von der Probenoberfläche entfernt ist. So kann die Probe auf atomarer Ebene untersucht werden. Damit das funktioniert, muss auch die Probe selbst elektrisch leitfähig sein. Doch da die Spitze die Probe nicht berührt, dürfte nach den Regeln der klassischen Physik eigentlich kein Strom fließen. Denn die nichtleitende Lücke stellt eine Potentialbarriere dar, bildhaft eine Wand, die für Elektronen nicht zu überwinden ist. Trotzdem lässt sich ein Strom messen. Die Erklärung liefert die Quantenphysik: In der Quantenphysik hat ein Elektron keine scharf definierte Position. Stattdessen lässt sich nur angeben, mit welcher Wahrscheinlichkeit es sich an einem bestimmten Ort aufhält. In Spitze und Probe haben die für den Stromfluss verantwortlichen freien Elektronen eine hohe Aufenthaltswahrscheinlichkeit, in der Lücke eine von Null. Doch die Aufenthaltswahrscheinlichkeit kann sich nicht abrupt ändern, sondern klingt an Grenzflächen exponentiell ab. Somit reicht sie sowohl von der Probe als auch von der Spitze aus ein Stück in die Lücke hinein. Ist der Abstand zwischen Spitze und Probe klein genug, überlappen die beiden abklingenden Aufenthaltswahrscheinlichkeiten und ein Elektron kann die Barriere durchdringen, ohne sie klassisch zu überwinden. Dieses Phänomen nennt man quantenmechanischen Tunneleffekt. Für ein einzelnes Elektron ist das Tunneln ein Zufallsereignis und lässt sich nicht vorhersagen. Für die große Zahl von Elektronen, die gemeinsam den Strom tragen, ist die Wahrscheinlichkeitsverteilung jedoch deterministisch. Das Ergebnis: Bei konstantem Abstand fließt ein konstanter, messbarer Tunnelstrom. Er ist mit typischerweise unter einem Nanoampere verschwindend klein. Ihn zu messen ist technisch sehr aufwendig.
Der entstehende Tunnelstrom hängt dabei stark vom Abstand zwischen Spitze und Probenoberfläche ab. Steigt der Abstand, so sinkt der Strom exponentiell. Dieser Zusammenhang wird beim Rastertunnelmikroskop ausgenutzt, um Proben genau zu untersuchen. Dazu wird die Spitze Linie für Linie über die Probe gerastert, wobei die Höhe der Spitze über der Probenoberfläche kontinuierlich so angepasst wird, dass der Tunnelstrom konstant bleibt (Konstanter-Strom-Modus, Abb. A). Die dafür nötige Änderung der Höhe wird aufgezeichnet. So lässt sich eine topografische Karte der Probe erstellen, die Höhenunterschiede mit extrem feiner Auflösung darstellt und einzelne Atome abbilden kann. Felix Küster nutzt solche Messungen, um das Ausgangsmaterial für seine Experimente genau zu charakterisieren. Dafür startet er mit einer kleinen Platte aus Niob, einem grauglänzenden Schwermetall (Abb. B). Niob ist supraleitend und das schon ab Temperaturen unter 10 K (–263 °C). Das ist die höchste kritische Temperatur unter allen elementaren Metallen (s. TECHMAX 5). Für alle weiteren Experimente ist entscheidend, dass die Oberfläche des Niob-Kristalls auf atomarer Ebene sauber ist. Das ist gar nicht so einfach zu bewerkstelligen, denn Niob reagiert an der Oberfläche mit Sauerstoff und bildet eine robuste Oxidschicht. „Den Niob-Kristall sauber zu kriegen ist ein richtiges Handwerk, das wir erst perfektionieren mussten. Unter anderem muss er mehrfach auf über 2.000 °C erhitzt werden“, sagt Felix Küster. Wenn alles geklappt hat, zeigt sich unter dem Rastertunnelmikroskop eine Oberfläche, in der die einzelnen Atome klar geordnet vorliegen (Abb. B).

Abb. B: Elementarer Supraleiter Niob als Ausgangsmaterial. Links: Ein 7 mm × 7 mm großer Niob-Kristall, der exakt entlang einer bestimmten Kristallachse geschnitten wurde. Mitte: Der Niob-Kristall wird im Vakuum mehrmals auf über 2.000 °C erhitzt, um eine auf atomarer Ebene saubere Oberfläche zu erzeugen. Rechts: Aufnahme des sauberen Niob-Kristalls mit dem Rastertunnelmikroskop, blau zeigt höhere, weiß niedrige Regionen an; die einzelnen Atome werden deutlich sichtbar.
© F. Küster, MPI für Mikrostrukturphysik
Mit dem sauberen Niob-Kristall hat Felix Küster Großes vor: Er möchte einen topologischen Supraleiter aus wenigen Atomen herstellen. Solche Supraleiter sind zwar theoretisch vorhergesagt und beschrieben, kommen aber nicht natürlich vor. Topologisch bedeutet hier, dass an den Rändern des Materials ein elektronischer Zustand existiert, der besonders geschützt ist und nicht durch eine lokale Störung verloren gehen kann. Gemeinsam mit weiteren Forschenden untersucht Felix Küster, ob er so einen topologischen Supraleiter erschaffen kann, indem er gezielt magnetische Atome auf der Oberfläche des Niob-Kristalls platziert. Dazu kühlt er das Niob mit flüssigem Helium auf 2 K (–271 °C) und dampft darauf anschließend geringste Mengen Chrom auf. Dabei treffen die Chromatome einzeln auf die extrem kalte Oberfläche des Niobs und frieren dort voneinander getrennt fest. Anschließend kühlt er das Material weiter auf 500 mK. Bei diesen Temperaturen ganz nahe am absoluten Nullpunkt ist Niob supraleitend. Die Elektronen liegen im Niob-Kristall dann als Cooper-Paare vor – zwei Elektronen mit entgegengesetztem Spin, die sich verlustfrei bewegen können (s. TECHMAX 5) .
Während Niob also supraleitend ist, sind die aufgedampften Chromatome magnetisch. Genau diese Kombination verspricht, der Schlüssel zur Entstehung topologischer Supraleiter zu sein. Der Magnetismus hat seinen Ursprung im Spin der Elektronen. Diese liegen in den äußeren Orbitalen der Chromatome einzeln, das heißt ungepaart, vor (Abb. C). Der Spin ist als Eigendrehimpuls der Elektronen eine quantenmechanische Eigenschaft mit zwei möglichen Zuständen. Diese Zustände werden oft als Pfeil nach oben bzw. unten dargestellt. Einzelne, diskrete Atomorbitale können maximal von zwei Elektronen besetzt werden. Und die müssen dann entgegengesetzte Spins aufweisen. Die Atomorbitale mit Spin-ungepaarten Elektronen führen zu einem permanenten magnetischen Moment, das wiederum mit dem Spin umliegender Elektronen wechselwirkt.
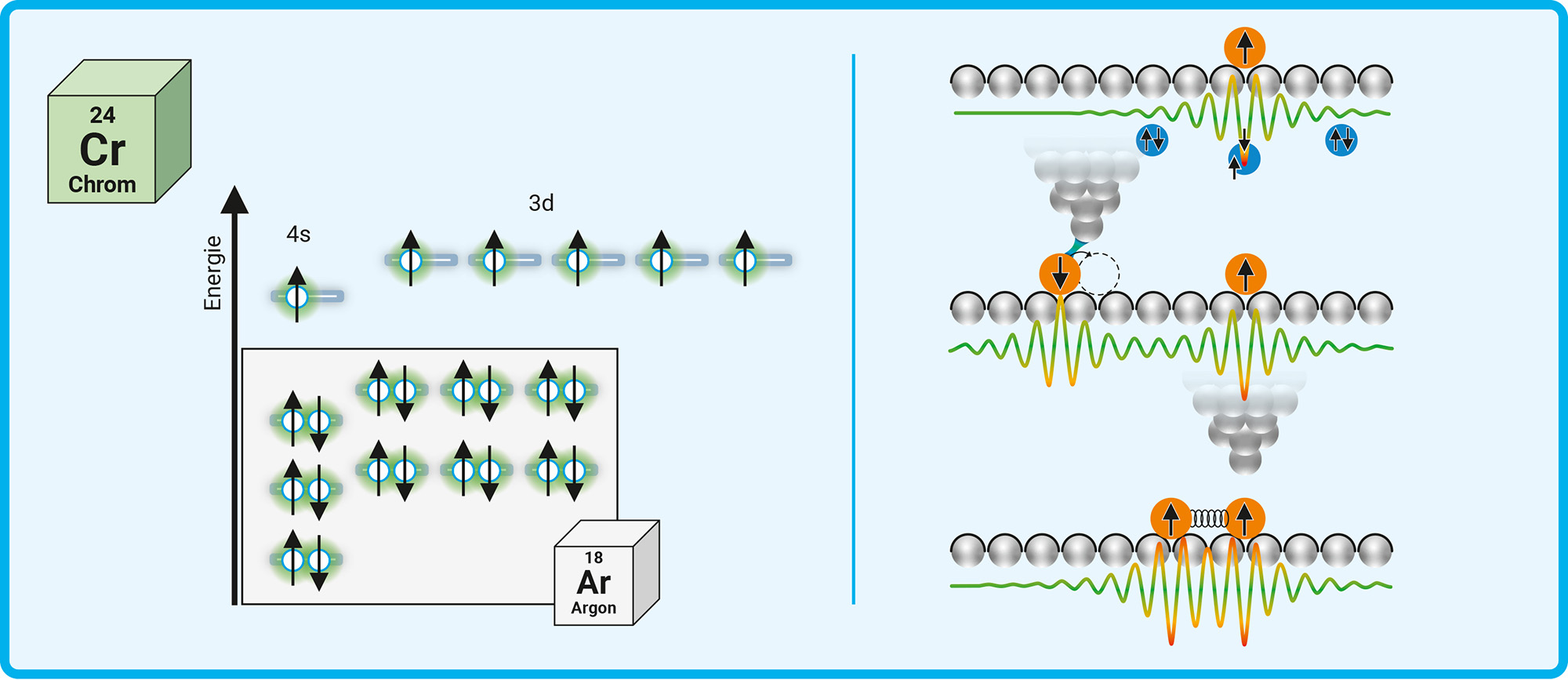
Abb. C: Magnetische Chromatome auf einem Supraleiter. Links: Chrom hat mit insgesamt sechs Spin-ungepaarten Elektronen in den äußeren 4s- und 3d- Orbitalen eine besondere Elektronenkonfiguration. Der Spin ist in der Abbildung als Pfeil dargestellt. Durch die ungepaarten Spins entsteht ein permanentes magnetisches Moment, das Chromatome magnetisch macht. Rechts: Ein Chromatom (orange) auf einer Niob-Oberfläche (grau) führt durch die Wechselwirkung der Spins dazu, dass lokal die supraleitenden Cooper-Paare (blau) aufgebrochen werden. An dieser Stelle bilden sich diskrete Zustände aus, hier durch eine Wellenfunktion dargestellt. Wenn mit der Spitze des Rastertunnelmikroskops ein zweites Chromatom nahe an ein anderes gebracht wird, kommt es zunächst zur Wechselwirkung (rechts, Mitte) und dann zur Hybridisierung (rechts, unten) dieser Zustände.
© links: F. Küster; rechts: Küster, F. et al. Long range and highly tunable interaction between local spins coupled to a superconducting condensate. Nat Commun 12, 6722 (2021) // CC BY 4.0
Da sowohl Supraleitung als auch Magnetismus vom Spin der Elektronen abhängig sind, können sie sich gegenseitig stören. Magnetismus könnte man also als Gegner der Supraleitung bezeichnen. So verdrängt ein Supraleiter üblicherweise ein Magnetfeld aus seinem Inneren. Doch wenn das Magnetfeld zu stark ist, wird die Supraleitung zerstört. Dort, wo die magnetischen Chromatome liegen, passiert das auf fast atomarer Ebene auch auf dem Niob-Kristall (Abb. C). Dadurch bilden sich rund um die Chromatome neue, diskrete Atomorbitale. Diskret bedeutet, dass die Elektronen, die sich im Orbital bewegen, nur bestimmte, deutlich voneinander getrennte Energieniveaus annehmen können. Das Besondere an den neuen Orbitalen rund um die Chromatome auf dem Niob-Kristall ist, dass sich darauf Elektronen mit Energien aufhalten können, für die es in Niob normalerweise keinen Platz gibt. Diese verbotene Zone im Energiespektrum, auch Bandlücke genannt, ist charakteristisch für Supraleiter.
Mit der Spitze des Rastertunnelmikroskops kann Felix Küster einzelne Chromatome auf der Oberfläche des Niob-Kristalls aufgreifen und gezielt an einer anderen Stelle platzieren (Abb. C). So konnte er in seinen Experimenten zunächst einzelne Chromatome und deren Umgebung untersuchen, bevor er anschließend immer komplexere Systeme schuf. Dazu brachte er als erstes ein zweites Chromatom immer näher an ein anderes heran. Dabei lässt sich zuerst eine schwache Wechselwirkung, bei noch geringerem Abstand eine sogenannte Hybridisierung beobachten. Die neuen diskreten Zustände, die für ein einzelnes Chromatom den Orbitalen eines Atoms entsprechen, bilden sich bei zwei eng beieinander liegenden Chromatomen dann analog eines Molekülorbitals aus. Anschließend stellte Felix Küster immer längere Ketten von Chromatomen und schließlich auch zweidimensionale Gitterstrukturen her (Abb. D). So bewerkstelligte er den Übergang vom Atom zum Molekül und erzeugte mit den Gittern schließlich einen Festkörper. Im Festkörper sind die Energieniveaus, auf denen sich Elektronen befinden können, nicht mehr diskret, sondern verschwimmen zu Bändern.
Zusammen mit Forschenden der theoretischen Physik wollte Felix Küster vor allem die Frage beantworten, ob die Elektronen im Chromatom-Gitter einen topologisch supraleitenden Zustand einnehmen können. Mit Hilfe der theoretischen Betrachtungen konnten die Forschenden einerseits festlegen, welche Atomanordnungen gebaut werden sollten, um dem topologischen Supraleiter nahe zu kommen. Und andererseits konnten sie die experimentellen Ergebnisse erst im Vergleich mit den Simulationen wirklich interpretieren. So nutzten sie das Phantombild, das die Theorie liefert, um den im Experiment gemessen Zustand zu identifizieren.
Auf der Suche nach den Spuren der topologischen Supraleitung untersuchten die Forschenden unter anderem die Zustandsdichte der Elektronen im Chromatom-Gitter. Als Eigenschaft eines Festkörpers beschreibt die Zustandsdichte, wie viele erlaubte Zustände es für Elektronen einer bestimmten Energie gibt. Während die diskreten Energieniveaus von einzelnen Atomorbitalen nur jeweils zwei Zustände besitzen, gibt man für die ausgedehnten Energiebänder im Festkörper die Zustandsdichte für ein bestimmtes Energiefenster an. „Die Zustandsdichte gewährt uns einen Einblick in das Zusammenspiel von Magnetismus und Supraleitung auf der Nanometerskala“, sagt Felix Küster. Für die Untersuchung nutzen die Forschenden wiederum das Rastertunnelmikroskop. Denn der Tunnelstrom hängt nicht nur vom Abstand zwischen Spitze und Probe ab, sondern auch von deren elektronischen Zustandsdichten. Misst man die Änderung des Tunnelstroms unter schrittweiser Änderung der angelegten Spannung (dI / dU), können Rückschlüsse auf die Zahl der Elektronenzustände gezogen werden (Spektroskopie-Modus des Rastertunnelmikroskops). In Kombination mit der räumlichen Auflösung des Mikroskops kann so ein Bild aufgezeichnet werden, das die Verteilung der Zustandsdichte auf der Oberfläche der Probe darstellt.
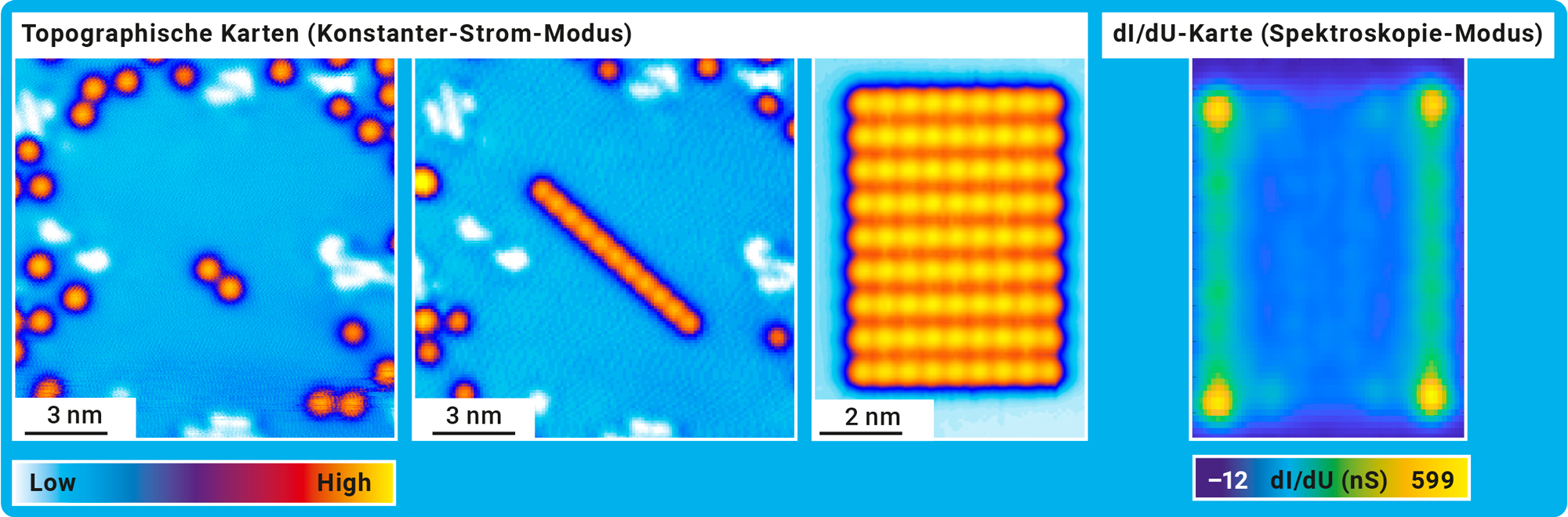
Abb. D: Lego spielen mit Atomen. Mit der Spitze des Rastertunnelmikroskops können Chromatome (orange) über die Niob-Oberfläche (blau) gezogen und exakt platziert werden. So lässt sich genau untersuchen, wie sich die Elektronenzustandsdichte verhält, wenn ein Atom alleine ist oder zwei eng beisammen sind (links) bzw. eine Kette (2. von links) oder ein Gitter (3. von links) gebildet wurde. Die erhöhte Elektronenzustandsdichte zeigt sich in den dI / dU-Bildern des Rastertunnelmikroskops als gelbe Region. Rechts ist beispielsweise ein Randzustand mit erhöhter Zustandsdichte zu sehen, der sich für das daneben dargestellte Gitter ausbildet.
© F. Küster, MPI für Mikrostrukturphysik
Die Ergebnisse zeigen erhöhte Zustandsdichten an den Rändern und Ecken der verschiedenen Chromatom-Gitter. Diese erscheinen in den dI / dU-Bildern des Rastertunnelmikroskops als helle Regionen (Abb. D). Der Vergleich mit dem theoretischen Modell legt nahe, dass die Forschenden erstmals einen Atom für Atom aufgebauten zweidimensionalen topologischen Supraleiter geschaffen haben. „Für den endgültigen Nachweis müssten wir noch größere Gitter aufbauen und die Messungen bei noch tieferen Temperaturen durchführen. Aktuell ist unsere Energieauflösung noch nicht hoch genug, und die gesuchten Signaturen können sich noch verstecken“, sagt Felix Küster. Aufregend sind aber auch schon die aktuellen Forschungsergebnisse. Denn topologisch geschützte supraleitende Zustände könnten Quantencomputer (s. TECHMAX 36) den entscheidenden Schritt voranbringen. Derzeitige Quantencomputer leiden vor allem an ihrer hohen Fehleranfälligkeit, man spricht von verrauschten Qubits. Sie sind extrem empfindlich gegenüber Umwelteinflüssen wie elektromagnetischer Strahlung, Temperaturschwankungen oder Vibrationen. Mit einem topologischen Supraleiter könnten topologische Qubits realisiert werden, die wesentlich robuster sind.
Abbildungshinweise:
Titelbild: © F. Küster, MPI für Mikrostrukturphysik
Abb. A: © F. Küster, MPI für Mikrostrukturphysik // CC BY-NC-SA 4.0
Abb. B: © F. Küster, MPI für Mikrostrukturphysik
Abb. C: © links: F. Küster; rechts: Küster, F. et al. Long range and highly tunable interaction between local spins coupled to a superconducting condensate. Nat Commun 12, 6722 (2021) // CC BY 4.0
Abb. D: © F. Küster, MPI für Mikrostrukturphysik
Der Text wird unter CC BY-NC-SA 4.0 veröffentlicht.
TECHMAX Ausgabe 41, Juni 2026; Text: Dr. Andreas Merian; Redaktion: Dr. Tanja Fendt
In der natürlichen Sprachverarbeitung ist eine Worteinbettung eine Darstellung eines Wortes. In der Regel handelt es sich bei der Darstellung um einen Vektor, der die Bedeutung des Wortes so kodiert, dass bei Wörtern, die im Vektorraum näher beieinander liegen, eine ähnliche Bedeutung zu erwarten ist. Der Vektor kann dabei vieldimensional sein, hier ist ein Beispiel in 2D dargestellt. Dabei werden Wörter gemäß ihrer Bedeutung in die Dimensionen Alter und Geschlecht eingeordnet.
© MPG
Im Wissensgraphen (links) repräsentieren die Kreise (Eckpunkte) wissenschaftliche Konzepte. Jedes Mal, wenn zwei Konzepte gemeinsam in einem Titel oder der Zusammenfassung einer wissenschaftlichen Arbeit erscheinen, wird eine Verbindungslinie (Kante) gezogen. Der gelbe und der blaue Teilgraph repräsentieren die Arbeit zweier Forschender, für die ein gemeinsamer Forschungsvorschlag gesucht wird. Die Merkmale der Konzepte im Wissensgraphen (Mitte) beeinflussen das Interesse an den Forschungsvorschlägen erheblich. Auf Grundlage dieser Daten wurde ein maschinelles Lernmodell trainiert, um den Grad des Interesses allein auf der Grundlage dieser Eigenschaften vorherzusagen. Als Lernmodell wurde ein kleines neuronales Netz (rechts) mit einer verborgenen Schicht und einem Ausgabeneuron genutzt (s. Techmax 34, Abb. B).
© Verändert nach: Gu & Krenn (2024): Generation and human-expert evaluation of interesting research ideas using knowledge graphs and large language models; OpenReview.net / CC BY 4.0
Im Universum gibt es unzählige Orte, über die wir noch sehr wenig wissen. Im Fokus der Forschung stehen sogenannte Exoplaneten, die um andere Sterne kreisen. Wie spüren Wissenschaftlerinnen und Wissenschaftler solche Himmelskörper auf und mit welchen Methoden untersuchen sie diese fernen Welten? Gibt es vielleicht sogar Leben auf einem Exoplaneten? In dieser Folge beantwortet Astrophysikerin Eva-Maria Ahrer vom Max-Planck-Institut für Astronomie die Fragen von Wissenschaftsjournalist Stefan Geier.
Audiodatei | 16 min, April 2026
© MPG / CC BY-NC-ND 4.0
