
Mithilfe von KI eine Filmsynchronisation nachbessern oder Science-Fiction-Figuren zum Leben erwecken? Mit seinem Team forscht der Informatiker Christian Theobalt an der Schnittstelle von Computer-Vision, Computer-Grafik und künstlicher Intelligenz.
Zum Podcast (36 min) vom 3. September 2025 © detektor.fm / Max-Planck-Gesellschaft
Inhalt
01:28 | Einleitung: KI für Filmsynchronisation
02:41 | Gab es einen Anlass, sich mit KI zu beschäftigen?
04:29 | Beispiele für Computer-Visual-Probleme
05:29 | Methoden in der Forschung, Beispiele für Forschungsfragen
06:49 | Warum will man die reale Welt mit KI simulieren?
08:40 | Forschungsprojekte für die Filmbranche: Motion-Capture-Verfahren optimieren
11:15 | Leistung der KI bei Motion-Capture-Verfahren
13:20 | Anwendungsbeispiele in der Medizin (Untersuchung des Bewegungsapparates)
14:29 | Einsatz von neuronalen Netzen in der Filmbranche: Visual Dubbing
17:02 | Stimmen imitieren mit KI?
19:06 | Kann man die Mimik in Echtzeit von einer Person auf eine andere übertragen?
21.40 | Anwendungen der Mimikerkennung (virtuelle Avatare)
24:31 | Risiken: Manipulation, Deep Fakes mit Hilfe von KI
27:41 | Wie kann man erkennen, was echt ist und was nicht?
29:58 | AI-Act: Kennzeichnung von KI-generierten Inhalten
31:20 | Umgang mit der rasanten Entwicklung von KI
33:50 | Vision zur Forschung?
Bild: © [M] MPG; Roboter im Atelier: [AI] Midjourney / MPG; Vitruvianischer Mensch: Leonardo da Vinci , Foto: Luc Viatour / ucnix.

© istockphoto.com / berya113
Forschende machen sich neugierig und motiviert auf die Suche nach neuem Wissen. Und mit einer guten Portion Kreativität und Ausdauer können sie Neues entdecken und verstehen. Künstliche Intelligenz ist zunehmend ein wichtiges Hilfsmittel, um dieses Ziel zu erreichen. Doch könnte die KI auch selbst als Wissenschaftlerin agieren, zu Erkenntnissen gelangen oder Ideen, Konzepte und echtes Verständnis entwickeln?
Noch nicht einmal fünf Jahre alt und schon das Abitur gut bestanden: Deutsch 2, Geschichte 2, Mathe 2, Ethik 2, Informatik 2. Die Hochbegabte: die künstliche Intelligenz (KI) ChatGPT, die auf einem großen Sprachmodell (large language model, LLM) basiert. Und wie sich anhand von Aufgaben aus dem bayerischen Abitur zeigte, war die 2023 verfügbare Version GPT-4 bereits so weit entwickelt, dass sie als gute Schülerin durchging und die allgemeine Hochschulreife zugesprochen bekam. Doch bedeutet das, dass die KI tatsächlich intelligent ist, oder plappert sie nur wie ein gut trainierter Papagei die richtigen Phrasen im richtigen Moment? Dass sie bekanntes Wissen korrekt und verständlich wiedergeben kann, hat KI schon gezeigt. Aber kann sie auch für die menschliche Intelligenz entscheidende Eigenschaften wie Neugier, Motivation und Kreativität entwickeln, Aufgaben eigenständig bearbeiten und sich eine eigene Meinung bilden? Mit diesen Fragen beschäftigt sich der Physiker Mario Krenn. Am Max-Planck-Institut für die Physik des Lichts und an der Eberhard Karls Universität Tübingen arbeitet er an einer KI, die Wissenschaftlerinnen und Wissenschaftler unterstützt oder sogar eigenständig forscht.
Zu dieser Forschung gelangte Krenn über die Quantenoptik. Im Jahr 2014 arbeitete er als Doktorand im Labor des späteren Nobelpreisträgers Anton Zeilinger in Wien daran, in komplexen optischen Aufbauten Lichtteilchen mit besonderen Eigenschaften herzustellen. Doch an einer Aufgabe biss Krenn sich monatelang die Zähne aus. Zusammen mit weiteren Forschenden versuchte er sich einen experimentellen Aufbau zu überlegen, der Lichtteilchen herstellt, die eine ganz bestimmte Beziehung zueinander haben. Egal wie er Laser, Linsen, Spiegel, Kristalle und Detektoren in seinen Gedankenexperimenten, Skizzen und Berechnungen anordnete, das erwünschte Ergebnis blieb aus. Also entschied Krenn sich dazu, ein Computerprogramm zu entwickeln, das sich auf die Suche nach der Lösung für sein Problem machen sollte. Dazu stattete er das Programm mit physikalischem Grundwissen aus und stellte alle optischen Bauteile virtuell zur Verfügung. „Damals wie heute setzen wir dazu sogenannte Explorationsalgorithmen ein, die den riesigen abstrakten Raum an Kombinationen sehr effizient auf neue Lösungen durchsuchen“, sagt Krenn. Melvin, wie Krenn sein Programm taufte, simulierte also Millionen von Kombinationen der Bauelemente und hatte damit schnell Erfolg. „Das war ein verrückter Tag. Ich konnte das gar nicht glauben. Das Programm hatte in ein paar Stunden eine Lösung gefunden, nach der drei experimentelle und ein theoretischer Physiker monatelang gesucht hatten“, erzählt Krenn. Anschließend sorgte er dafür, dass Melvin dazulernen konnte. Dank eines Algorithmus des maschinellen Lernens erinnert sich das Programm an bereits simulierte Aufbauten und versucht, diese für die Lösung des neuen Problems wiederzuverwerten.
Ausgehend von diesem Erfolg untersucht Krenn, wie KI der Forschung helfen und zu neuen Erkenntnissen beitragen kann. Schon heute ist KI ein wichtiges Hilfsmittel: So kann beispielsweise AlphaFold, das auf tiefen neuronalen Netzen basiert, eine Proteinstruktur auf Grundlage der Aminosäuresequenz vorhersagen. Dies ermöglicht es, genau auf eine Anwendung zugeschnittene Proteine herzustellen. Und deren Potenzial ist riesig, etwa in der Medizin oder chemischen Industrie. Doch neues Verständnis hat AlphaFold bisher nicht produziert. So sagt das Programm zwar voraus, wie die Struktur eines Proteins einer bestimmten Aminosäuresequenz aussieht, erklärt aber nicht, warum es diese Form annimmt oder wie die Faltung abläuft.
Krenn wünscht sich aber eine KI, die mehr ist als eine Blackbox, die ein Ergebnis produziert. Daher untersucht er, wie KI auf unterschiedlichen Ebenen zu neuem Verständnis beitragen kann (Abb. A). In der ersten Dimension dient KI als Instrument, das Eigenschaften eines Systems aufdeckt, die sonst nur schwer oder gar nicht zu ergründen sind. Menschen können aus diesen Erkenntnissen dann wissenschaftliches Verständnis entwickeln. Dies gilt vor allem für die Simulation von natürlichen Prozessen, die auf Längen- und Zeitskalen ablaufen, die im Experiment nicht wahrnehmbar sind. In der zweiten Dimension dient die KI als Inspirationsquelle für neue Konzepte und Ideen, die menschliche Forschende verstehen und verallgemeinern können. So kann die KI Überraschungen in Datensätzen oder der Literatur finden. Oder unerwartete Konzepte entdecken, indem sie wissenschaftliche Modelle untersucht oder mit einprogrammierter Neugier oder Kreativität einen Datenraum exploriert. Und auch wenn die KI Lösungen für bestimmte Probleme beziehungsweise Aufgaben in interpretierbarer Form ausgibt, kann sie als Inspirationsquelle für die Entdeckung neuer Konzepte dienen. In diesen ersten beiden Dimensionen ermöglicht die KI also dem Menschen, neue wissenschaftliche Erkenntnisse zu gewinnen. In der dritten Dimension gewinnt die Maschine selbst neue Erkenntnisse und damit Verständnis und kann dieses auch weitergeben. In diese Dimension ist KI bisher nicht vorgedrungen.
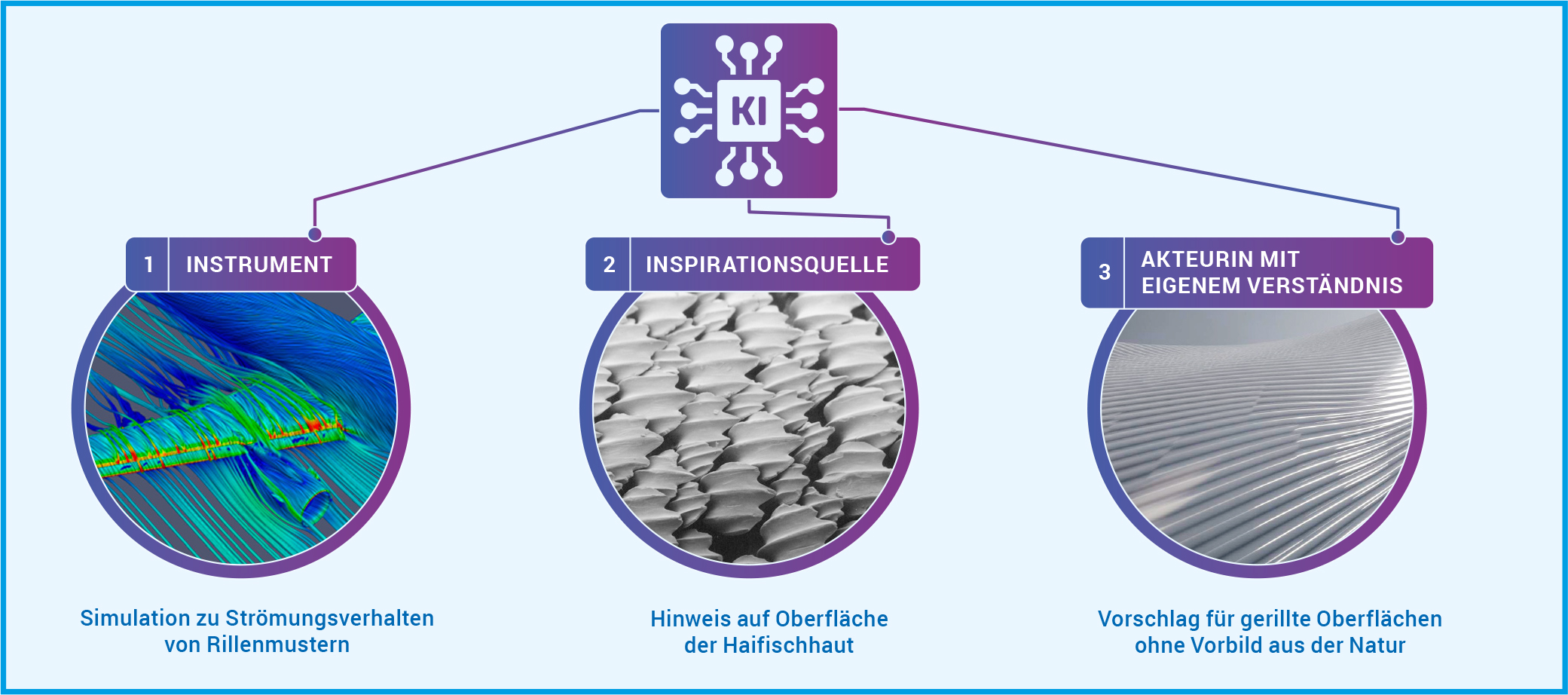
Abb. A: KI kann auf drei Dimensionen zu neuem Verständnis beitragen. [ 1 ] Als Instrument, das Eigenschaften eines physikalischen Systems aufdeckt, die sonst nur schwer oder gar nicht zu ergründen sind. Bei der Haifischhaut hätte eine KI durch Simulationen die Experimente in einem Strömungskanal ersetzen können. [ 2 ] Als Inspirationsquelle, die überraschende Ideen und Konzepte findet. Die KI hätte etwa Forschende aus der Luft- und Raumfahrt auf die Beobachtungen des Wirbeltierforschers aufmerksam machen können, der die Rillen auf den Haifischschuppen entdeckte. [ 3 ] Als Agentin des Verständnisses, die selbst in der Lage ist, wissenschaftliches Verständnis zu entwickeln und weiterzugeben. So eine Agentin hätte auch ohne das biologische Vorbild der Haifischhaut auf derartige Rillen kommen können, um den Strömungswiderstand von Flugzeugen zu reduzieren.
© DLR (CC BY-NC-ND 3.0), Pascal Deynat/Odontobase (CC BY-SA 3.0), MPG (CC BY-NC-SA 4.0)
Mario Krenn arbeitet aktuell an einer KI als Inspirationsquelle. Zusammen mit seiner Kollegin Xuemei Gu entwickelte er SciMuse, die Wissenschafts-Muse: Ein System, das neue, personalisierte Forschungsideen vorschlägt. Dazu stützten sich die Forschenden einerseits auf GPT-4 und setzten andererseits auf einen selbst entwickelten Wissensgraphen (Abb. B). Der Wissensgraph enthält Informationen zum Inhalt und Einfluss von mehr als 58 Millionen wissenschaftlichen Artikeln. Während der Entwicklung von SciMuse nutzten die Forschenden entweder eine Kombination aus ihrem Wissensgraphen und GPT-4 oder GPT-4 alleine, um Forschungsvorschläge zu generieren. Dabei beinhalteten die Prompts für GPT-4 die Aufforderung zur Selbstreflexion: GPT-4 sollte drei Ideen entwickeln, reflektieren und zweimal verbessern. Und dann die am besten geeignete Projektidee als Endergebnis auswählen. Eine derartige Selbstreflexion ist in zahlreichen aktuellen LLM-KIs bereits enthalten, so auch in der GPT-4 Nachfolgerin o3. Diese sogenannten Reasoning-Modelle überprüfen ihre eigenen Ergebnisse schrittweise, bevor sie eine Antwort geben.
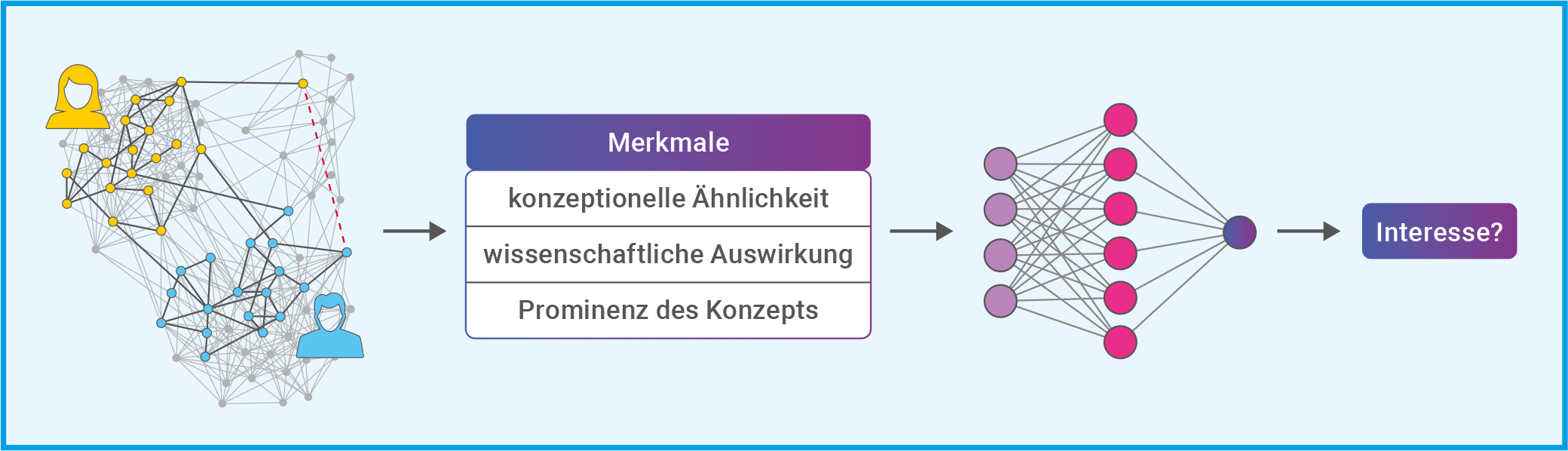
Abb. B: Im Wissensgraphen (links) repräsentieren die Kreise (Eckpunkte) wissenschaftliche Konzepte. Und jedes Mal, wenn zwei Konzepte gemeinsam in einem Titel oder der Zusammenfassung einer wissenschaftlichen Arbeit erscheinen, wird eine Verbindungslinie (Kante) gezogen. Der gelbe und der blaue Teilgraph repräsentieren die Arbeit zweier Forschender, für die ein gemeinsamer Forschungsvorschlag gesucht wird. Die Merkmale der Konzepte im Wissensgraphen (Mitte) beeinflussen das Interesse an den Forschungsvorschlägen erheblich. Auf Grundlage dieser Daten wurde ein maschinelles Lernmodell trainiert, um den Grad des Interesses allein auf der Grundlage dieser Eigenschaften vorherzusagen. Als Lernmodell wurde ein kleines neuronales Netz (rechts) mit einer verborgenen Schicht und einem Ausgabeneuron genutzt (s. Techmax 34, Abb. B).
© Verändert nach: Gu & Krenn (2024): Generation and human-expert evaluation of interesting research ideas using knowledge graphs and large language models; OpenReview.net / CC BY 4.0
Krenn und Gu legten im nächsten Schritt einhundert erfahrenen Max-Planck-Forschenden die KI-generierten, personalisierten Forschungsvorschläge vor. In einer Umfrage bewerteten diese das Interessensniveau der Vorschläge. Die Ergebnisse zeigten, dass die Forschungsvorschläge, die mittels einer Kombination von Wissensgraph plus GPT-4 erstellt wurden, nicht besser abschnitten als jene, die von GPT-4 alleine erzeugt wurden. Doch anhand der Bewertungen konnten die Forschenden klare Zusammenhänge zwischen Interessensniveau des Forschungsvorschlags und Eigenschaften nachweisen, die die zugrunde liegenden Konzepte im Wissensgraphen aufwiesen (Abb. B). Anhand dieser Zusammenhänge trainierte Krenns Team ein kleines neuronales Netz für die Vorhersage des Forschungsinteresses allein aus Daten des Wissensgraphen. Damit hatten sie die KI mit einem Gefühl für spannende Forschungsthemen ausgestattet und so SciMuse geschaffen. Dank dieses Gefühls kann SciMuse neue und hochinteressante Forschungsthemen aus Wissensgraphen auswählen und mit Hilfe moderner großer Sprachmodelle vollwertige Forschungsvorschläge formulieren.
GPT-4 konnte Krenns Team nicht auf die gleiche Weise mit Gefühl ausstatten. Denn während sie im selbst entwickelten Wissensgraphen bestimmte Eigenschaften ausmachen konnten, die das Interessensniveau beeinflussen, haben sie keinen Einblick in die Arbeitsweise von GPT-4. LLMs wie GPT-4 sind meist eine Blackbox, die so komplex ist, dass niemand genau versteht, wie sie auf ihre Ergebnisse kommt. Ein LLM basiert auf einem künstlichen neuronalen Netz, das auf die Verarbeitung und Erzeugung von natürlicher Sprache spezialisiert ist. Ein oftmals genutzter Ansatz, um ein LLM zu erzeugen, ist der generative vortrainierte Transformer (generative pre-trained transformer, GPT). Dieser ist darauf spezialisiert, Text zu verarbeiten und zu erzeugen. Dabei wird Text in numerische Repräsentationen (Token) umgewandelt. Jedes Token wird gemäß einer Worteinbettungstabelle (word embedding) in einen Vektor umgewandelt und so in Kontext gesetzt (Abb. C). Das künstliche neuronale Netz trainiert bei GPTs auf riesigen Datensätzen unmarkierten Textes (unüberwachtes Lernen). Zur Feinabstimmung wird überwachtes Lernen und Verstärkungslernen durch menschliches Feedback eingesetzt.
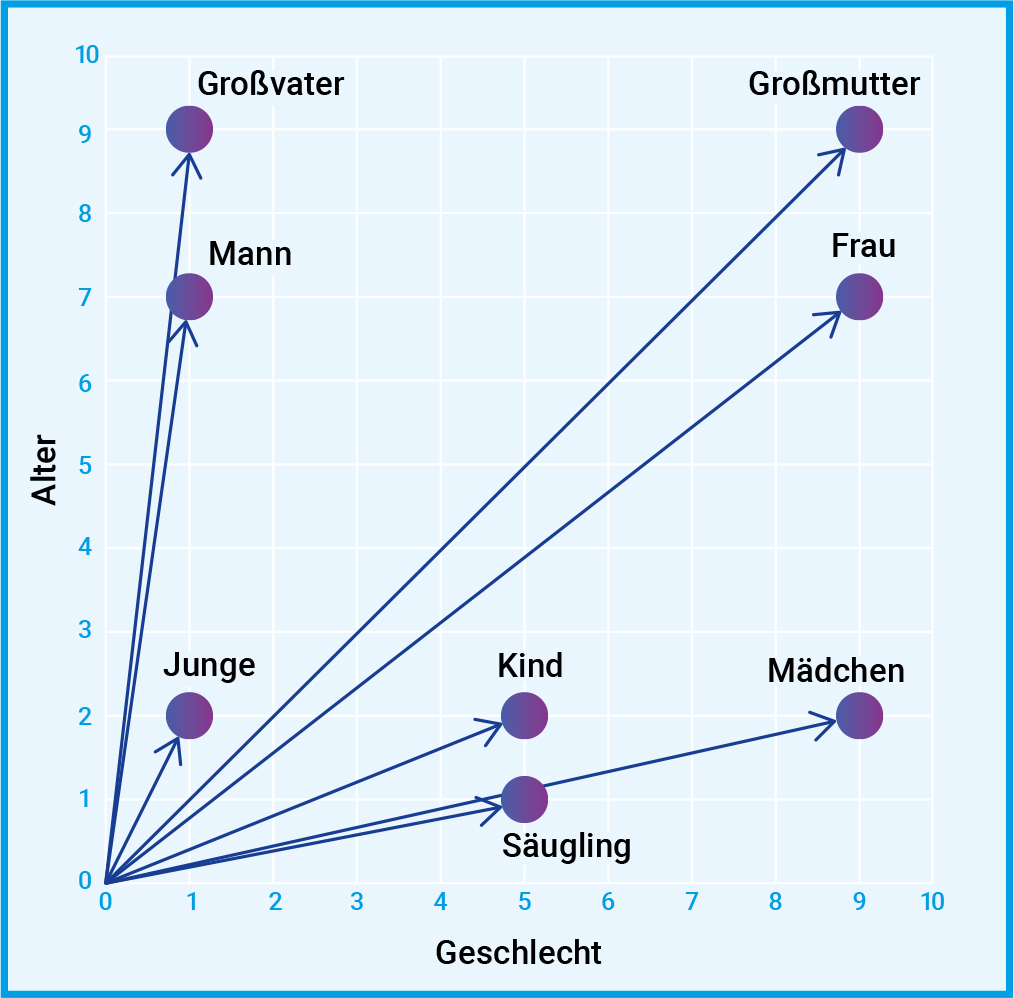
Abb. C: In der natürlichen Sprachverarbeitung ist eine Worteinbettung eine Darstellung eines Wortes. In der Regel handelt es sich bei der Darstellung um einen Vektor, der die Bedeutung des Wortes so kodiert, dass bei Wörtern, die im Vektorraum näher beieinander liegen, eine ähnliche Bedeutung zu erwarten ist. Der Vektor kann dabei vieldimensional sein, hier ist ein Beispiel in 2D dargestellt. Dabei werden Wörter gemäß ihrer Bedeutung in die Dimensionen Alter und Geschlecht eingeordnet.
© MPG
Wann forscht KI besser als wir?
Aktuelle große Sprachmodelle wirken schon erstaunlich intelligent. Im Fall der Reasoning-Modelle sprechen einige Fachleute sogar davon, dass diese Modelle nun logisch denken können. Kritiker bezweifeln dies und sehen den Schritt hin zur allgemeinen künstlichen Intelligenz (artificial general intelligence, AGI) noch in weiter Ferne. Unter AGI versteht man eine KI, die eigene Schlüsse zieht, sowie Bekanntes und Gelerntes auf neue Felder übertragen kann. Außerdem sollte eine AGI in einer natürlichen, das heißt einer komplexen und offenen Umgebung zurechtkommen. Wenn es um die Bewertung der Intelligenz einer KI geht, wird es schnell philosophisch. Denn es ist nicht ganz klar, was intelligent genau bedeutet. Schon heute überflügeln KIs den Menschen in zahlreichen Kategorien des rationalen Denkens. Doch bisher scheitern KIs daran, auf unerwartete Veränderungen zu reagieren oder ihr Gelerntes auf Gebiete anzuwenden beziehungsweise zu übertragen, die nicht ihrem Training entsprechen. Eine KI, die selbst als Wissenschaftlerin agieren soll, müsste genau das schaffen, um neue Erkenntnisse zu gewinnen und Verständnis zu entwickeln. Denn Verständnis setzt eine intuitive, modell- oder bildhafte Vorstellung eines wissenschaftlichen Zusammenhangs voraus. Diese Vorstellung ermöglicht es dann, qualitative Aussagen zu treffen, ohne genaue Berechnungen anzustellen.
Für die KI als Wissenschaftlerin sind außerdem auch Neugier, Kreativität und Motivation wichtig. Dazu braucht sie eine Beziehung zur realen Welt. Denn um spannende, das heißt bedeutende Probleme beziehungsweise Fragen zu identifizieren, muss sie wissen, was ihr selbst oder für die ganze Menschheit wichtig ist. Dieses sogenannte Weltwissen ist bei KIs bisher wenig ausgeprägt. Das liegt an den eingeschränkten Trainingsdaten, die KIs bisher zum Lernen nutzen. Zwar könnte man bei großen Sprachmodellen wie ChatGPT davon sprechen, dass sie sich durch die enorme Anzahl an verarbeiteten Texten Weltwissen angeeignet haben. Doch auch ihnen fehlt der vieldimensionale Bezug zur Welt, weil sie im Gegensatz zum Menschen keine verkörperten Intelligenzen sind: Sie können nicht physisch mit der realen Welt interagieren und auch nur sehr eingeschränkt Sinneseindrücke sammeln. Während also ein Mensch sowohl Auto fahren als auch wissenschaftliche Erkenntnisse gewinnen kann, ist dies für KIs momentan noch eine Herausforderung.
Mario Krenn bewertet die Fähigkeiten von KI als Wissenschaftlerin aktuell so: „Wir sind jetzt auf dem Niveau, auf dem wir Ideen erzeugen können. Und bei bestimmten Themen können unsere KI-Systeme bereits vollkommen neue Lösungen für wissenschaftliche Fragestellungen finden!“ Für die Zukunft ist er optimistisch und hofft, dass die KI ihre menschlichen Kolleginnen und Kollegen auf der Suche nach neuen Erkenntnissen bald kräftig unterstützt.
Abbildungshinweise:
Titelbild: © istockphoto.com / berya113
Abb. A: © DLR (CC BY-NC-ND 3.0), Pascal Deynat/Odontobase (CC BY-SA 3.0), MPG (CC BY-NC-SA 4.0)
Abb. B: © Verändert nach: Gu & Krenn (2024): Generation and human-expert evaluation of interesting research ideas using knowledge graphs and large language models; OpenReview.net / CC BY 4.0
Abb. C: © MPG
Der Text wird unter CC BY-NC-SA 4.0 veröffentlicht.
TECHMAX Ausgabe 39, August 2025; Text: Dr. Andreas Merian; Redaktion: Dr. Tanja Fendt
Zwei Podcast-Folgen beleuchten verschiedene Aspekte zum Einsatz künstlicher Intelligenz in der Medizin.
KI und bildgebende Verfahren
Zum Podcast (28 min) vom 9. Juli 2025 © detektor.fm / Max-Planck-Gesellschaft
Themen: Deep Learning // Explainable Artificial Intelligence // Auswertung von MRT-Bildern mit KI
KI in der Biomedizin
Zum Podcast (35 min) vom 12. Juni 2025 © detektor.fm / Max-Planck-Gesellschaft
Themen: Ethische Fragen beim Einsatz von KI im Gesundheitswesen // Oszillierende Neuronale Netze // KI hilft bei der Berechnung von biologischen Abläufen
Kann ein KI-gesteuerter Roboter in der Natur alleine „überleben“, wie im neuen Kinofilm „Der wilde Roboter“? Diese Frage beantworten Forschende vom Max-Planck-Institut für Intelligente Systeme in Tübingen. Zusammen mit Doktor Whatson (Cedric Engels) analysieren sie nicht nur die fiktionalen Technologien, die im Film präsentiert werden, sondern auch die realen Herausforderungen, denen sich Roboter- und KI-Entwickler in der Realität gegenübersehen. Die Wissenschaftlerinnen und Wissenschaftler zeigen, wo die Möglichkeiten und Grenzen der Robotik in Bezug auf natürliche Umgebungen und KI aktuell liegen.
[Dauer des Videos: 50 min]

Zum Film auf YouTube: https://youtu.be/VIJPvPB2_nA
Inhalt (Mit Transkript und Kapitelmarkern auf YouTube)
– Wir bauen einen wilden Roboter
– Überlebt KI in der Wildnis?
– Kann ein Roboter eine Mutter sein?
– Roboter und Emotionen
– Braucht es General AI?
– Roboter in der Landwirtschaft
– Können wir KI vertrauen?
– Kann ein Roboter über seine Programmierung hinauswachsen?
– Roboter mit „Fingerspitzengefühl“
– Selbstreparierende Roboter
– Kann man einen „wilden Roboter“ bauen?
– Fazit
Hintergrundinformationen:
Roboter entdecken die Welt
Haptischer Sensor für Roboter
Intelligente Roboter, Chatbots, wie ChatGPT oder Bildgeneratoren wie Midjourney – auch wenn künstliche Intelligenz in aller Munde ist: Was ist KI, wie funktioniert so ein Chatbot und was hat das Moravecsche Paradox damit zu tun?
Um diese Frage zu beantworten, müssen wir nicht unbedingt verstehen, wie ein Computer funktioniert. Aber es hilft zu verstehen, wie ein KI-Computeralgorithmus zu seinem Wissen kommt. Also: Wie lernt künstliche Intelligenz?
In diesem Video erklärt Cedric Engels die gängigsten Lernmethoden von künstlicher Intelligenz wie zum Beispiel überwachtes und unüberwachtes Lernen und verstärkendes Lernen. Dafür hat Cedric Engels das Max-Planck-Institut für Intelligente Systeme in Tübingen besucht. Dort wird mit maschinellem Lernen an Robotern geforscht, um ihnen beizubringen, Tischtennis zu spielen oder in einem Windkanal zu schweben.
[Dauer des Videos: 16 min]

YouTube-Link: https://youtu.be/dFReVjQMF6U
Ein einfaches Modell eines neuronalen Netztes, das für Deep Learning genutzt wird, besteht aus mehreren Schichten künstlicher Neuronen (Kugeln). Die Eingabeschicht (blaue Kugeln) nimmt die eingehenden Daten auf. Diese werden anschließend von den Neuronen in den verborgenen Schichten (hier nur eine Schicht, gelbe Kugeln) verarbeitet. Dazu werden die Daten von einem künstlichen Neuron gewichtet (Gewicht wxx) und an weitere Neuronen in der nächsten Schicht weitergegeben. Das Ergebnis des Programms in der Ausgabeschicht hängt somit von vielen verschiedenen Neuronen und Gewichten ab (rote Linien).
© Grafik: HNBM, CC BY-NC-SA 4.0

© [M] MPG; Roboter im Atelier: [AI] Midjourney / MPG; Vitruvianischer Mensch: Leonardo da Vinci , Foto: Luc Viatour / ucnix.
Der Avatar folgt den Bewegungen Theobalts exakt, und das in Echtzeit. Während der Wissenschaftler seinen Vortrag hält, spricht, gestikuliert und bewegt sich auch sein virtueller Doppelgänger. Neben dem realistischen Abbild des Wissenschaftlers zeigt der Bildschirm parallel auch zwei einfache Modelle (Abb. A). Diese sind üblicherweise nicht zu sehen, verdeutlichen aber, auf welcher Grundlage die Bewegungen des aus vier Blickwinkeln durch Kameras aufgezeichneten Wissenschaftlers auf den Avatar übertragen werden. Christian Theobalt spricht von holoportierten Charakteren, die in virtuellen Räumen zum Einsatz kommen können. Er sagt: „So könnte in Zukunft beispielsweise eine virtuelle Telepräsenz möglich sein, die es erlaubt, über große Distanzen mit Personen realistisch zu kommunizieren, ohne reisen zu müssen.“
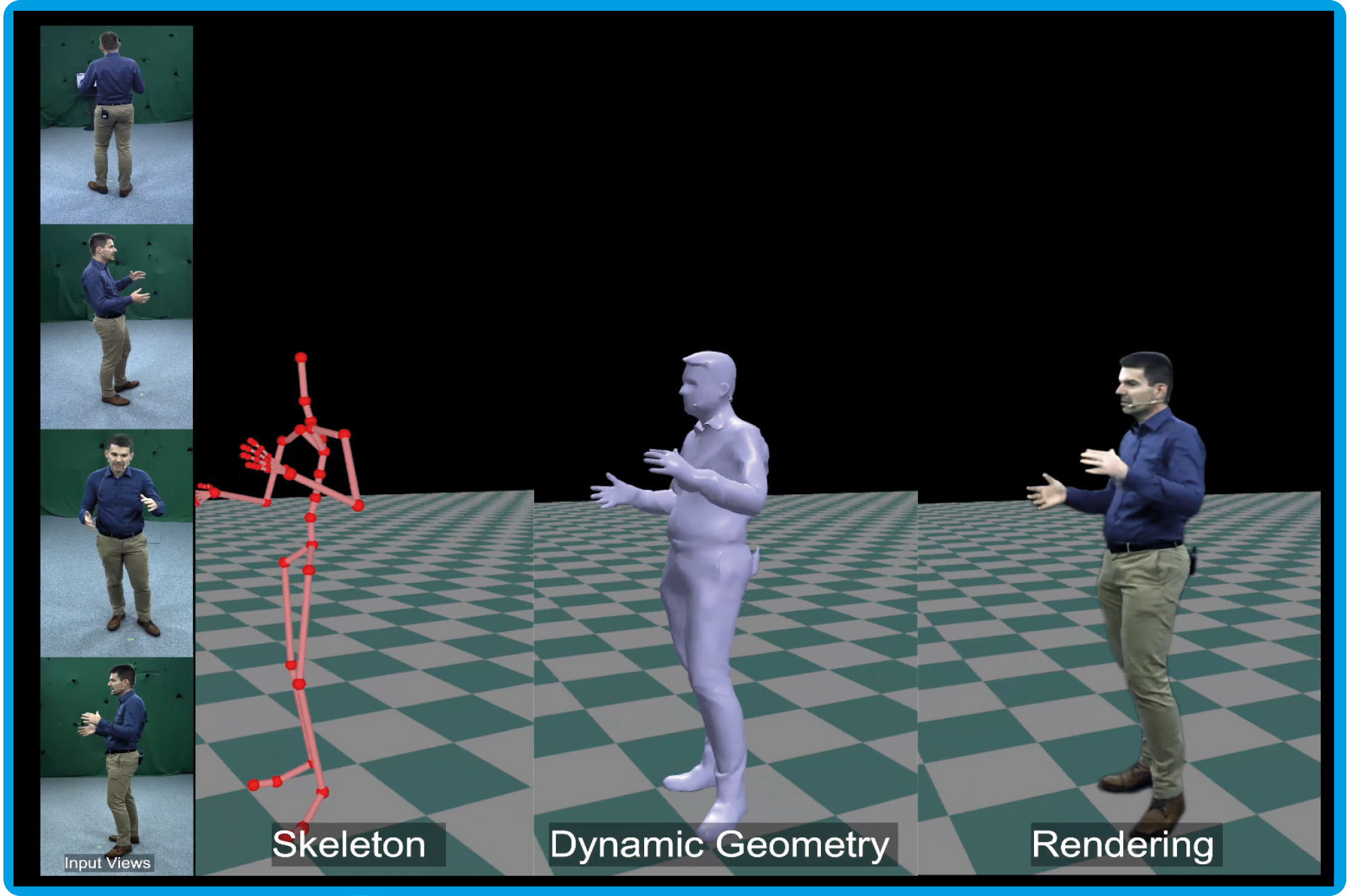
Abb. A: Ein Avatar entsteht. Das von Theobalts Team erstellte und trainierte KI-Programm kann anhand von Kamerabildern, die aus vier Blickwinkeln aufgenommen werden (links), ein virtuelles 3D-Abbild einer Person erschaffen (rechts). Dieses lässt sich dann aus jedem beliebigen Blickwinkel betrachten bzw. darstellen und in virtuellen Treffen oder Computerspielen einsetzen. Damit der Avatar realistisch und detailgetreu ist, extrahiert das Programm zunächst die 3D-Skelettpose aus den Kamerabildern. Anschließend wird eine dynamische Textur bzw. Oberfläche erstellt und schließlich der hochaufgelöste Avatar erzeugt.
© MPI für Informatik, Universität Saarbrücken, Via Research Center; arXiv:2312.07423
Anhand des holoportierten Wissenschaftlers erklärt Christian Theobalt viele Facetten seiner Arbeit. Sein Ziel ist es, neue Wege zu entwickeln, die bewegte, reale Welt technisch zu erfassen und so detailgetreue virtuelle Modelle zu erstellen. Diese Modelle sollen es Computern und zukünftigen intelligenten Maschinen ermöglichen, die reale Welt zu verstehen, sicher mit ihr zu interagieren oder sie auch zu simulieren. Bislang ist es sehr aufwendig, Bewegungen technisch aufzuzeichnen und in allen Einzelheiten mittels Computergrafik wiederzugeben. Für die technische Erfassung von Bewegungen, Motion Capture genannt, werden meist viele Kameras und Marker kombiniert oder eine Tiefenkamera verwendet. Bei der digitalen Erzeugung von Bildern wird außerdem viel Aufwand betrieben, damit Bewegungen natürlich erscheinen oder Details wie Lichtreflexionen, Falten in der Kleidung oder die Mimik von Menschen möglichst realistisch wiedergegeben werden. Für Filme erstellen und bearbeiten Spezialisten die computergenerierten Bilder, kurz CGI (engl. Computer Generated Imagery) in aufwendiger Handarbeit. Christian Theobalt will das alles wesentlich vereinfachen: „Ziel ist es, dass eine einzige Kamera ausreicht, um Bewegungen exakt zu erfassen.“ Und auch Bilder zu erzeugen oder zu verändern soll wesentlich einfacher werden. Dazu forscht Theobalts Abteilung „Visual Computing and Artificial Intelligence“ an der Schnittstelle von Computergrafik, Computer Vision und künstlicher Intelligenz. Der erwünschte Fortschritt soll durch die Kombination künstlicher Intelligenz und etablierter Ansätze der Computergrafik, wie beispielsweise der Nutzung geometrischer Modelle, erreicht werden.
Der Begriff künstliche Intelligenz beschreibt Algorithmen, die dazu dienen, Maschinen intelligent zu machen. In vielen Fällen ahmen diese Algorithmen die kognitiven Fähigkeiten von Menschen nach. Ziel der Forschung und Entwicklung im Bereich der künstlichen Intelligenz ist es, Maschinen zu schaffen, die in bestimmten Bereichen der Intelligenz an den Menschen heranreichen oder diesen sogar übertreffen. Eine gebräuchliche Abkürzung für künstliche Intelligenz ist KI. Im englischsprachigen Raum wird von „artificial intelligence“ gesprochen und manchmal wird die daraus folgende Abkürzung AI auch im Deutschen verwendet.
Die menschliche Intelligenz zeichnet sich dadurch aus, dass das Gehirn unseren Körper steuert, Sinneseindrücke verarbeitet und neue Informationen mit bekannten verbindet. Dadurch können wir Geschehnisse in unserer Umwelt einordnen und vorausschauend denken und handeln. Bekannte Bereiche der künstlichen Intelligenz sind die Robotik, also die Steuerung komplexer Bewegungen, und Computerprogramme, die komplexe Spiele wie Schach oder Go meistern und dafür Informationen verarbeiten und vorausschauend agieren müssen. Eine weitere Komponente der Intelligenz ist das Sprachverständnis. Das Ziel des Forschungsbereichs der Computerlinguistik ist es, Maschinen zu entwickeln, die Sprache möglichst umfassend verstehen. Zuletzt machten auf diesem Feld sogenannte Chatbots wie ChatGPT oder Bard Schlagzeilen, aber auch Übersetzungsprogramme wie DeepL gehören zu den vielfältigen Anwendungen von KI im Bereich Sprache. Der Aspekt an künstlicher Intelligenz, der Christian Theobalt am meisten interessiert, ist das Visual Computing. Darunter fallen alle digitalen Methoden, die Bilder verarbeiten, analysieren, modifizieren und erzeugen. Seine Arbeit geht also über die Computer Vision hinaus, die aus visuellen Daten wie Bildern und Videos Informationen gewinnt und beispielsweise in selbstfahrenden Fahrzeugen zum Einsatz kommt.
In seiner Forschung setzt Theobalt auf maschinelles Lernen. Diese Art des Lernens produziert künstliche Intelligenz, die nicht auf vorab formulierten Regeln basiert, sondern aus Beispielen lernt, wie eine Entscheidung zu treffen ist. Stehen der selbstlernenden Maschine hunderte oder besser tausende Beispiele zum Training zur Verfügung, entwickelt sie selbstständig einen Entscheidungsprozess, der verallgemeinert werden kann. Somit ist dieser anschließend auch auf unbekannte Datensätze anwendbar. Dazu nutzt Theobalts Forschungsteam das Deep-Learning-Verfahren. Dieses imitiert das menschliche Lernverhalten und basiert auf einem neuronalen Netz. Das Netz besteht aus künstlichen Neuronen, die in mehreren Schichten den Entscheidungsprozess gestalten (Abb. B). Jedes Neuron verarbeitet die eingehenden Daten, indem es die einzelnen Eingabegrößen gewichtet und gemäß bestimmter Regeln an die Neuronen der nächsten Schicht weitergibt. Nachdem moderne neuronale Netze oftmals aus vielen Schichten bestehen und damit tief sind, spricht man von Deep Learning.
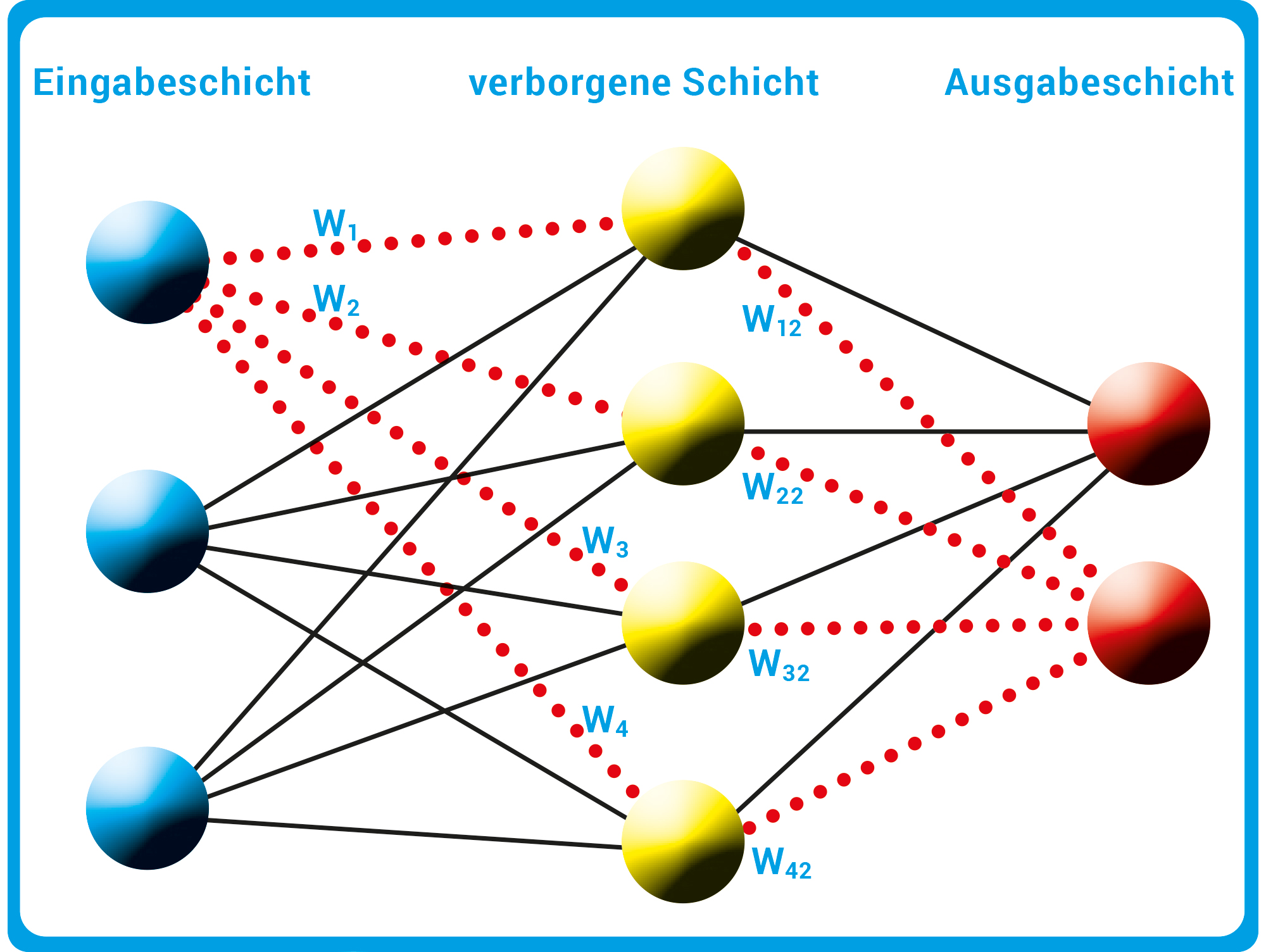
Abb. B: Neuronales Netz. Ein einfaches Modell eines neuronalen Netztes, das für Deep Learning genutzt wird, besteht aus mehreren Schichten künstlicher Neuronen (Kugeln). Die Eingabeschicht (blaue Kugeln) nimmt die eingehenden Daten auf. Diese werden anschließend von den Neuronen in den verborgenen Schichten (hier nur eine Schicht, gelbe Kugeln) verarbeitet. Dazu werden die Daten von einem künstlichen Neuron gewichtet (Gewicht wxx) und an weitere Neuronen in der nächsten Schicht weitergegeben. Das Ergebnis des Programms in der Ausgabeschicht hängt somit von vielen verschiedenen Neuronen und Gewichten ab (rote Linien).
© Grafik: HNBM, CC BY-NC-SA 4.0
Der rasante Fortschritt der letzten Jahre auf dem Gebiet der KI basiert auf solchen selbstlernenden Programmen. Ausgelöst wurde diese Entwicklung durch Forschungserfolge im Deep Learning ab 2009 sowie immer größere verfügbare Rechenleistung und Datenmengen (Big Data), die es möglich machen, eine KI umfassend zu trainieren. So konnten Programmierende die Fähigkeiten von KI-Programmen rasch verbessern und erweitern. Beispielsweise erzielte 2015 das Deep-Learning-basierte Programm AlphaGo die ersten Erfolge einer KI gegen Weltklassespieler beim Brettspiel Go. Im weniger komplexen Schach schaffte es dagegen schon 1997 der Schachcomputer Deep Blue, den amtierenden Weltmeister zu schlagen. Deep Blue war eine regelbasierte, sogenannte symbolische KI. Diese Art der KI ist nicht selbstlernend, sondern kommt zu Entscheidungen, indem sie anhand klarer, vorab im Programmcode festgelegter Regeln Symbole wie z. B. Wörter oder Ziffern kombiniert. Die rein regelbasierte KI ist allerdings stark limitiert. Denn abgesehen von Spielen wie Schach, in denen die Umgebung eindeutig definiert ist, versagt sie, da es kaum möglich ist, alle möglichen Fälle vorab durch Regeln abzudecken. Der Vorteil symbolischer KI ist, dass sie durch die Regeln und Symbole in der menschlichen Realität verankert ist und ihre Entscheidungen somit nachvollziehbar und interpretierbar sind. Im Gegensatz dazu sind die Entscheidungen selbstlernender Programme nicht per se nachvollziehbar. Christian Theobalt kombiniert in seiner Forschung regelbasierte und selbstlernende KI im sogenannten neuro-expliziten Verfahren. Wenn die KI etwa lernen soll, menschliche Bewegungen aus Kamerabildern zu rekonstruieren, nutzt sein Team ein vereinfachtes Skelett mit erlaubten Bewegungsrichtungen und -winkeln, um die Entscheidungen des Programms in realistische Bahnen zu lenken.
Damit die KI später gute Entscheidungen trifft, sind die Trainingsdaten entscheidend. Dabei ist es sowohl wichtig, dass eine große Datenmenge verfügbar ist, als auch, dass diese Daten von hoher Qualität sind. Damit der Avatar von Theobalt erzeugt werden kann, posierte der Wissenschaftler vorab in einem speziellen Labor vor mehr als einhundert hochauflösenden Kameras. Für das Trainingsdatenset der neuro-expliziten KI wird einerseits ein statischer 3D-Scan von Theobalt mit dem vereinfachten Skelett versehen und andererseits Videomaterial aufgezeichnet, das die unterschiedlichsten Bewegungen und Körperhaltungen aus allen Blickwinkeln umfasst. Ein Teil des Videomaterials dient außerdem als Testdatenset. Die trainierte KI kann anschließend auf der Grundlage von Videomaterial aus nur vier Blickwinkeln den detailgetreuen, bewegten Avatar erstellen. „Der Avatar kann Bewegungen darstellen und Haltungen annehmen, die nicht im Trainingsdatenset enthalten sind. Und er kann aus jedem Blickwinkel betrachtet werden, also nicht nur aus den vier Kameraperspektiven der Eingangsdaten“, sagt Christian Theobalt.
Dazu startet das Programm mit den vier Kamerabildern, der extrahierten 3D-Skelett-Pose und den Kameraparametern (Abb. A). Das auf Basis des Trainingsdatensets erstellte neuronale Netz für das Charaktermodell nimmt die Skelett-Bewegung als Eingabe und sagt eine positionsabhängige Verformung des Gitters voraus, das die Oberfläche des Charaktermodells bildet. Anschließend wird die Textur der Person soweit möglich aus den vier Kamerabildern gewonnen. Die Textur umfasst die Oberflächenbeschaffenheit und Farbe, etwa von Haut, Haaren und Kleidung. Im nächsten Schritt erstellt ein weiteres neuronales Netz aus diesen Texturinformationen eine blickwinkelabhängige, dynamische Textur. Zu guter Letzt erzeugt ein weiteres neuronales Netz aus den gesamten, niedrig aufgelösten Merkmalen die hochaufgelösten Bilder des Avatars. Das ganze Programm aus mehreren zusammenspielenden neuronalen Netzwerken arbeitet so schnell, dass der Avatar in Echtzeit entsteht und keine Verzögerung zwischen den Bewegungen der realen Person und dem holoportierten Charakter festzustellen ist.
Der Lernprozess der neuronalen Netze, die Theobalts Team dazu nutzt, läuft überwacht ab. Beim überwachten Lernen hat der Algorithmus eine klare Zielvorgabe und nutzt das Trainingsdatenset, um diesem Ziel immer näher zu kommen. Im Fall des Avatars werden die Ergebnisse der neuronalen Netze mit den zugrundeliegenden Kamerabildern verglichen, um eine möglichst fotorealistische Darstellung zu erreichen. Weitere wichtige Formen des maschinellen Lernens sind das unüberwachte Lernen und das bestärkende Lernen.
Das Gesicht und die Hände sind die Körperpartien, die am schwierigsten technisch nachzustellen sind. Doch gerade Mimik und Handgesten werden in Zukunft wichtig für die Interaktion von Menschen mit Computer- und Robotersystemen sein. Daher liegt hier auch ein Schwerpunkt von Theobalts Forschung: Sein Team arbeitet daran, mit nur einer Kamera die Bewegung von Händen oder die Details eines Gesichts erfassen zu können. Ihre Forschung zu Gesichtern zeigt, dass sich der Gesichtsausdruck einer Person in einem Quellvideo auf eine Person in einem Zielvideo übertragen lässt. Die Forschenden entwickelten beispielsweise ein Programm, das die detaillierten Bewegungen der Augenbrauen, des Mundes, der Nase und der Kopfposition aufzeichnet. Dadurch kann etwa der ganze Ausdruck eines Synchronsprechers auf den eigentlichen Schauspieler im Film übertragen werden, wodurch die Synchronisation eines Films in einer anderen Sprache wesentlich vereinfacht wird. Noch realistischer wirkt die Synchronisation durch eine weitere Entwicklung des Forschungsteams: Die stilbewahrende Lippensynchronisation überträgt die Mimik der Quellperson (Synchronsprecherin) auf den charakteristischen Stil der Zielperson (Schauspielerin) (Abb. C). Dadurch passen die Lippenbewegungen zur neuen Tonspur, während die Eigenheiten, die die Schauspielerin ausmachen, erhalten bleiben. Dazu nutzen die Forschenden einen ähnlichen Ansatz wie für den holoportierten Charakter. Die neuro-explizite KI stützt sich in diesem Fall auf ein Gesichtsmodell und neuronale Netze.

Abb. C: Realistische Mimik. Die KI-gestützte visuelle Synchronisation kann die Lippen stilbewahrend an eine neue Tonspur anpassen, indem sie die Mimik der Quellperson auf den charakteristischen Stil der Zielperson überträgt. Wird der Gesichtsausdruck dagegen direkt übertragen, gehen die Eigenheiten, die die Zielperson ausmachen, verloren. Dies wird hier beispielsweise an der Mundpartie deutlich.
© H. Kim et al.: Neural Style-Preserving Visual Dubbing (2019)
Neben vielen zukunftsträchtigen Anwendungen, die solche Forschung erschließt, birgt diese Technik auch Gefahren. Mithilfe derartiger Programme ist es möglich, Medieninhalte zu fälschen, die für einzelne Personen, aber auch ganze Gesellschaften zur Gefahr werden können. Diese durch Deep Learning erzeugten Fälschungen werden Deepfakes genannt und sind ein echtes Problem: gerade in niedrig aufgelösten Videos, die in sozialen Medien kursieren, sind Fälschungen mit bloßem Auge kaum zu identifizieren. So können falsche Informationen schnell und durchaus glaubhaft verbreitet werden. Politikern oder Politikerinnen können zu Propagandazwecken falsche Aussagen in den Mund gelegt und Prominenten kann ein künstlicher Skandal angehängt werden. Letztlich kann prinzipiell jeder Mensch, von dem Video- oder Bildmaterial zugänglich ist, Opfer eines Deepfakes werden. Theobalt plädiert dafür, dass Forschende die Ausgabe ihrer Programme mit einem Wasserzeichen versehen, das es später ermöglicht, damit erzeugte Deepfakes leicht zu identifizieren. Außerdem sagt er: „Es wird immer Menschen geben, die Technik missbrauchen. Der beste Weg, um dagegen vorzugehen, ist mit dem Fortschritt Schritt zu halten und KI-basierte Programme auch dafür zu nutzen, gefälschte Bilder oder Videos aufzuspüren. Wir entwickeln mit unserer Forschung auch das mathematische Verständnis, das dazu nötig ist, Fälschungen zu detektieren.“ Aktuell ist es meist noch möglich, Deepfake-Videos selbst zu identifizieren. Doch dazu muss man sehr aufmerksam sein und auf Details wie Lippenbewegungen, Zähne und Mundinnenraum, Augenpartie oder Schattenwurf und Reflexionen achten. Allerdings werden die Algorithmen immer besser und gefälschte Videos immer schwerer von der Wirklichkeit zu unterscheiden. Forschende entwickeln daher Programme, die Deepfakes verlässlich aufdecken sollen. Diese können allerdings wiederum dazu genutzt werden, die erzeugenden KI-Programme noch besser zu machen. Ein Wettrüsten findet statt. Entsprechend ist es nach Ansicht vieler Experten entscheidend, den Einsatz von KI umfassend gesetzlich zu regulieren, damit diese Technologie sicher und zum Wohl der Menschen eingesetzt wird.
Abbildungshinweise:
Titelbild © [M] MPG; Roboter im Atelier: [AI] Midjourney / MPG; Vitruvianischer Mensch: Leonardo da Vinci , Foto: Luc Viatour / ucnix.
Abb. A: © MPI für Informatik, Universität Saarbrücken, Via Research Center; arXiv:2312.07423; https://doi.org/10.48550/arXiv.2312.07423
Abb. B: © Grafik: HNBM / CC BY-NC-SA 4.0
Abb. C: © H. Kim et al.: Neural Style-Preserving Visual Dubbing (2019); https://arxiv.org/abs/1909.0251
Der Text wird unter CC BY-NC-SA 4.0 veröffentlicht.
TECHMAX Ausgabe 34, Frühjahr 2024; Text: Dr. Andreas Merian; Redaktion: Dr. Tanja Fendt
